PyTreeEditor help
So far, only "Configuration" has been explained. Additional chapters to be followed.
Contents:
- 1 Configuration
- 1.1 Delimiter
- 1.2 Data prefix / data delimiter
- 1.3 Ignore prefix
- 1.4 Data as expandable tree elements
- 1.5 Highlighted (colored) signal words
- 1.6 Default configuration values for known programs
1 Configuration
With the help of this configuration window you can change the way the files are interpreted. Additionally the text color of words (e.g. signal words) can be changed.
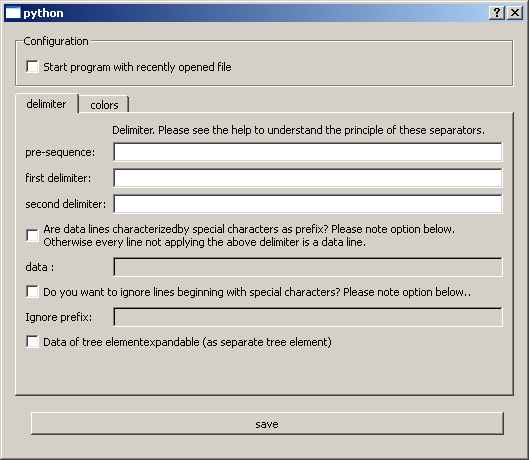
1.1 Delimiter
Please select the pre-sequence, first delimiter and second delimiter. These are required to separate the words of a whole line. The first and second delimiter are optional (could be left empty: ""). One or more characters can be used for these delimiters. To understand these elements, please see the following example (from the presentation picture):
ExampleFile.txt
1: @GROUP_A FirstElementA | Appendix1
2: *ITEM 115 0 1
3: *SEG D.Fu-0-6-1
4: *ITEM HUU -100 0
5: *ITEM Z_Z 1 2
6:
7: ;Sample comment
8: @GROUP_Foo Foo1 | Footext
9: *ITEM F1 16 0 10
You may have noticed that line 1 and 8 didn't contain the last part (beginning with | ). Also the line 7 beginning with ; didn't exist.
Now let's assume which delimiter configuration may be useful for this kind of structure / pattern. In the example file above lines 1 and 8 have something in common.
Let's have a look at line 1:
1: @GROUP_A FirstElementA | Appendix1
Our goal is to extract the three words of this identifier line:
GROUP_A, FirstElementA and
Appendix1.
The identifier lines typically begin with an @ , so let's choose @ as the pre-sequence.
The following word (until the first delimiter if existing) will be used as first word of the identifier line:GROUP_A.
A word is currently defined to consist of the following characters: a-z or A-Z or 0-9 or one of the following characters , ; & . # + - / *( ) { } _
Therefore delimiter cannot contain one of these characters because the program might not recognize this delimiter (because it is part of the word).
The exact definition of a word is required because regular expressions are used to find identifier lines.
Please note: If the first delimiter and second delimiter aren't defined, the first (and only) word of the identifier line will be: GROUP_A FirstElementA | Appendix1
Now the part of the line 1 with the gray background is covered:
@GROUP_A FirstElementA | Appendix1
In the text file above the blank separates the first from the second word.
Therefore let's choose a blank as first delimiter. The following word (consider the word definition with the allowed characters above) is taken as second word of the identifier line: FirstElementA
Please note: If no second delimiter is defined the second word of the identifier line is: FirstElementA | Appendix1
Preliminary result of the coverage:
@GROUP_A FirstElementA | Appendix1
The " | " (blank|blank) separates the second from the third word. After you've chosen this as second delimiter, Appendix1 will be taken as second word of the identifier line.
Now all three words are covered.
The program will show uncovered lines after the import process in a remainder list window. This helps you to adjust the delimiters.
1.2 Data prefix / data delimiter
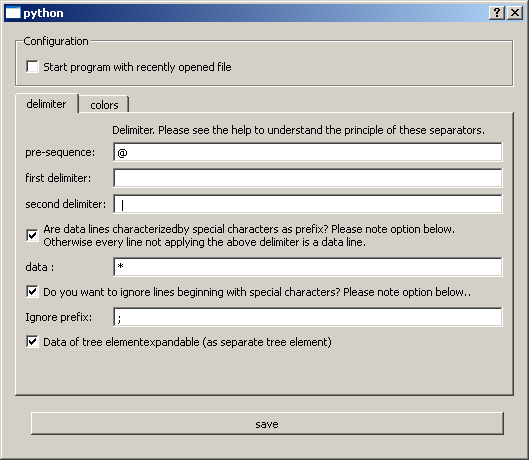
Select the checkbox "Are data lines characterized by ..." when data elements begin a with special prefix.
The asterisk character * is such a data prefix in the example file as can be seen in the excerpt of line
2: *ITEM 115 0 1
After the checkbox is checked, the line below is editable and the prefix (in this case *) can be entered. From now on, only lines beginning with this prefix are treated as data lines. Other lines (which are no identifier lines) are ignored and listed in a remainder list window after the import.
It is also possible to uncheck this option and the prefix won't be considered.
When the prefix isn't used (unchecked option), all lines are treated as data lines, except the one probably configured with ignore prefix (see chapter 1.3 Ignore prefix).
1.3 Ignore prefix
Analogous to the option from chapter 1.2 Data prefix / data delimiter, the checkbox and line are available to ignore lines beginning with a special prefix. The example file contains a line beginning with a semicolon character ; in line 7:
;Sample comment
These comment lines will be ignoed by selecting the checkbox and inserting a semicolon (;).
The following picture shows the current configuration:
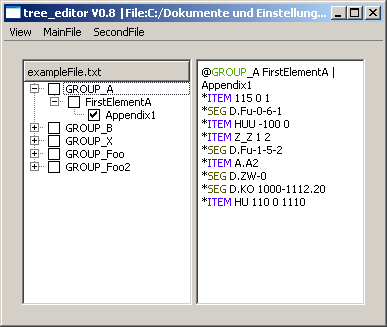
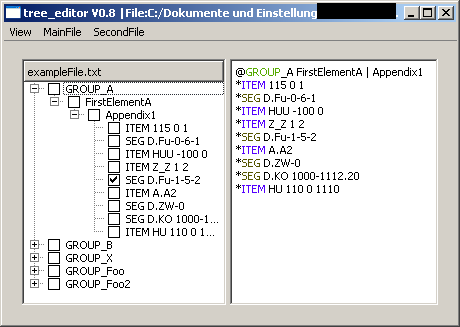
1.4 Data as expandable tree elements
The data lines can be displayed in the editor of the corresponding selected tree elements or as child tree element of the corresponding tree element. Use the checkbox "Data of tree elements ..." to configure your desired behavior.
The first picture shows the main window with data and the second one with data as tree elements.
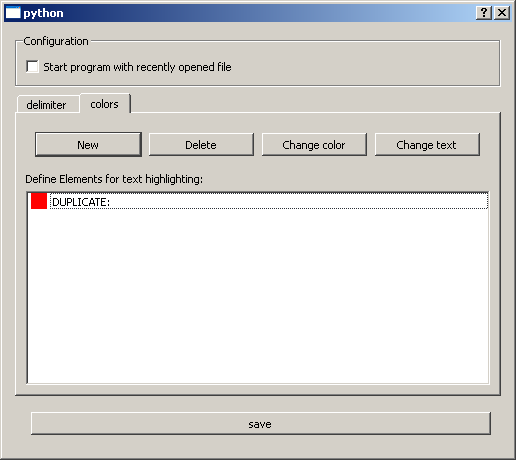
1.5 Highlighted (colored) signal words
Words of the editor can be highlighted. Add a new entry to the list, where black is the default font. Use the appropriate button to change the color of the selected entry of the list. Other buttons make it possible to change the text or to delete the selected entry of the list.
The red DUPLICATE: is a default value which will be used in a report shown up after the import process of a file. It can be deleted.
Highlighted words can be seen in the pictures of chapter 1.4 Data as expandable tree elements.
1.6 Default configuration values for known programs
The following values can be used for the given programs.
Please send me the values of your configuration and the program to use for via e-mail (see contact page).
- LaTeX:
- pre-sequence:\
- Ignore prefix:%
- The option of chapter 1.4 Data as expandable tree elements should be disabled for files over 1 MB because it takes to long to import.
- Pleaes set all other options to unchecked / empty ("")
- LS-Dyna
- pre-sequence:*
- Ignore prefix:$
- The option of chapter 1.4 Data as expandable tree elements should be disabled for files over 1 MB because it takes to long to import.
- Pleaes set all other options to unchecked / empty ("")